Contents
- TensorFlow - 구글 머신러닝 플랫폼
- 1. 텐서 기초 살펴보기
- 2. 간단한 신경망 만들기
- 3. 손실 함수 살펴보기
- 4. 옵티마이저 사용하기
- 5. AND 로직 연산 학습하기
- 6. 뉴런층의 속성 확인하기
- 7. 뉴런층의 출력 확인하기
- 8. MNIST 손글씨 이미지 분류하기
- 9. Fashion MNIST 이미지 분류하기
- 10. 합성곱 신경망 사용하기
- 11. 말과 사람 이미지 분류하기
- 12. 고양이와 개 이미지 분류하기
- 13. 이미지 어그멘테이션의 효과
- 14. 전이 학습 활용하기
- 15. 다중 클래스 분류 문제
- 16. 시냅스 가중치 얻기
- 17. 시냅스 가중치 적용하기
- 18. 모델 시각화하기
- 19. 훈련 과정 시각화하기
- 20. 모델 저장하고 복원하기
- 21. 시계열 데이터 예측하기
- 22. 자연어 처리하기 1
- 23. 자연어 처리하기 2
- 24. 자연어 처리하기 3
- 25. Reference
- tf.cast
- tf.constant
- tf.keras.activations.exponential
- tf.keras.activations.linear
- tf.keras.activations.relu
- tf.keras.activations.sigmoid
- tf.keras.activations.softmax
- tf.keras.activations.tanh
- tf.keras.datasets
- tf.keras.layers.Conv2D
- tf.keras.layers.Dense
- tf.keras.layers.Flatten
- tf.keras.layers.GlobalAveragePooling2D
- tf.keras.layers.InputLayer
- tf.keras.layers.ZeroPadding2D
- tf.keras.metrics.Accuracy
- tf.keras.metrics.BinaryAccuracy
- tf.keras.Sequential
- tf.linspace
- tf.ones
- tf.random.normal
- tf.range
- tf.rank
- tf.TensorShape
- tf.zeros
Tutorials
- Python Tutorial
- NumPy Tutorial
- Matplotlib Tutorial
- PyQt5 Tutorial
- BeautifulSoup Tutorial
- xlrd/xlwt Tutorial
- Pillow Tutorial
- Googletrans Tutorial
- PyWin32 Tutorial
- PyAutoGUI Tutorial
- Pyperclip Tutorial
- TensorFlow Tutorial
- Tips and Examples
13. 이미지 어그멘테이션의 효과¶
적은 수의 이미지 데이터를 가지고 Neural Network를 훈련할 때 과적합 (overfitting) 문제가 발생할 수 있습니다. 과적합이란 훈련에 사용되는 이미지에 과도하게 학습되어서 새로운 이미지를 제대로 인식하지 못하는 현상입니다.
또한 훈련에 사용되는 이미지가 적기 때문에 훈련 과정에서 보지 못한 유형의 이미지를 인식하지 못할 수 있습니다. 예를 들어, 아래와 같이 훈련 과정에서 왼쪽의 신발들을 사용한 후에 오른쪽의 하이힐을 인식하면 신발로 분류하지 못할 수 있습니다.

또한, 훈련 과정에서 왼쪽의 고양이 이미지들을 학습한 후에 오른쪽의 누워있는 고양이의 이미지를 인식하지 못할 수 있습니다.

이미지 어그멘테이션 (Image augmentation)은 이미지 인식에 있어서 과적합 문제를 해결하기 위한 매우 간단하면서 강력한 이미지 전처리 기법입니다.
이미지 어그멘테이션 기법을 사용하면 훈련 과정에서 즉석해서 이미지를 회전 (rotation)시키는 등의 변화를 적용합니다.
이 페이지에서는 이미지 어그멘테이션 기법을 이용해서 데이터를 전처리함으로써
적은 수의 이미지 데이터셋을 이용해서 이미지 인식의 정확도를 높이고 과적합 문제를 개선하는 과정에 대해 소개합니다.
순서는 아래와 같습니다.
이미지 데이터 전처리하기¶
이미지 어그멘테이션을 위해서 이전의 예제에서 다루었던 tf.keras.preprocessing.image 모듈의 ImageDataGenerator 클래스를 수정합니다.
ImageDataGenerator 클래스를 이용한 이미지 데이터 전처리에 대해서는 먼저 고양이와 개 이미지 분류하기 페이지를 참고하세요.
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# train_datagen = ImageDataGenerator(rescale = 1.0/255.)
train_datagen = ImageDataGenerator(rescale = 1.0/255.,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
test_datagen = ImageDataGenerator(rescale = 1.0/255.)
ImageDataGenerator 클래스의 rescale 파라미터의 값을 1.0/255로 지정하면 모든 값을 255로 나누게 됩니다.
rotation_range는 이미지를 임의로 회전시키는 각도를 지정합니다. 0~180 사이의 값을 입력합니다.
width_shift, height_shift는 이미지를 임의로 수직 또는 수평 방향으로 이동시키는 범위를 지정합니다. 이미지의 너비 또는 높이에 대한 비율로 지정합니다.
shear_range는 전단변환 (shearing transformation)을 위한 파라미터입니다. 이미지를 어긋나 보이도록 변환합니다.
zoom_range는 이미지를 임의로 확대하는 정도를 지정합니다.
horizontal_flip은 이미지를 임의로 (수평 방향으로) 뒤집을지 여부를 결정합니다.
fill_mode는 회전 또는 이동 변환 후 빈 픽셀을 채우는 방식을 지정합니다. 디폴트는 ‘nearest’이며, {‘constant’, ‘nearest’, ‘reflect’, ‘wrap’} 중 하나의 값으로 지정합니다.
더 자세한 내용은 링크를 참고하세요.
정확도와 손실 확인하기¶
import matplotlib.pyplot as plt
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training accuracy')
plt.plot(epochs, val_acc, 'b', label='Validation accuracy')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'go', label='Training Loss')
plt.plot(epochs, val_loss, 'g', label='Validation Loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
앞의 예제에서와 마찬가지로 Matplotlib 라이브러리를 이용해서 훈련 과정에서의 정확도와 손실을 확인해보겠습니다.
아래와 같은 결과가 출력됩니다.
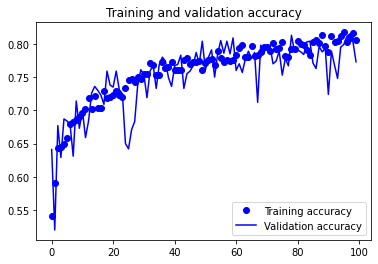
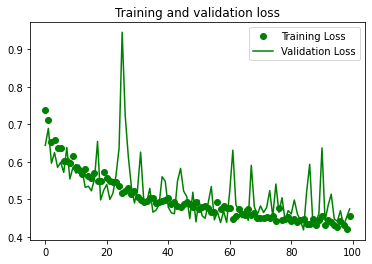
이미지 어그멘테이션 (Image augmentation)을 사용하지 않았던 결과와 비교해보면,
훈련 데이터와 테스트 데이터에 대한 정확도, 손실 값이 일치하는 경향을 보이고, 과적합 (Overfitting) 현상이 두드러지게 감소했음을 알 수 있습니다.
또한 이미지 어그멘테이션 과정에서 이미지 변환의 임의성 (Randomness)이 반영되어서 최종 정확도 (약 0.80)는 이미지 어그멘테이션을 사용하지 않은 경우의 훈련 데이터에 대한 정확도 (약 1.0)보다는 감소했음을 알 수 있습니다.
이미지 어그멘테이션 기법을 적용하면 메모리 저장 공간을 차지하지 않고, 적은 수의 이미지 데이터로 매우 다양한 훈련 데이터를 사용하는 효과가 있습니다. 하지만 훈련 과정에서 즉시 이미지 프로세싱이 이루어지기 때문에 훈련 시간이 증가하게 됩니다.