Contents
- TensorFlow - 구글 머신러닝 플랫폼
- 1. 텐서 기초 살펴보기
- 2. 간단한 신경망 만들기
- 3. 손실 함수 살펴보기
- 4. 옵티마이저 사용하기
- 5. AND 로직 연산 학습하기
- 6. 뉴런층의 속성 확인하기
- 7. 뉴런층의 출력 확인하기
- 8. MNIST 손글씨 이미지 분류하기
- 9. Fashion MNIST 이미지 분류하기
- 10. 합성곱 신경망 사용하기
- 11. 말과 사람 이미지 분류하기
- 12. 고양이와 개 이미지 분류하기
- 13. 이미지 어그멘테이션의 효과
- 14. 전이 학습 활용하기
- 15. 다중 클래스 분류 문제
- 16. 시냅스 가중치 얻기
- 17. 시냅스 가중치 적용하기
- 18. 모델 시각화하기
- 19. 훈련 과정 시각화하기
- 20. 모델 저장하고 복원하기
- 21. 시계열 데이터 예측하기
- 22. 자연어 처리하기 1
- 23. 자연어 처리하기 2
- 24. 자연어 처리하기 3
- 25. Reference
- tf.cast
- tf.constant
- tf.keras.activations.exponential
- tf.keras.activations.linear
- tf.keras.activations.relu
- tf.keras.activations.sigmoid
- tf.keras.activations.softmax
- tf.keras.activations.tanh
- tf.keras.datasets
- tf.keras.layers.Conv2D
- tf.keras.layers.Dense
- tf.keras.layers.Flatten
- tf.keras.layers.GlobalAveragePooling2D
- tf.keras.layers.InputLayer
- tf.keras.layers.ZeroPadding2D
- tf.keras.metrics.Accuracy
- tf.keras.metrics.BinaryAccuracy
- tf.keras.Sequential
- tf.linspace
- tf.ones
- tf.random.normal
- tf.range
- tf.rank
- tf.TensorShape
- tf.zeros
Tutorials
- Python Tutorial
- NumPy Tutorial
- Matplotlib Tutorial
- PyQt5 Tutorial
- BeautifulSoup Tutorial
- xlrd/xlwt Tutorial
- Pillow Tutorial
- Googletrans Tutorial
- PyWin32 Tutorial
- PyAutoGUI Tutorial
- Pyperclip Tutorial
- TensorFlow Tutorial
- Tips and Examples
22. 자연어 처리하기 1¶
이제 TensorFlow를 이용해서 자연어를 처리하는 방법에 대해서 알아봅니다.
이 페이지에서는 우선 tensorflow.keras.preprocessing.text 모듈의 Tokenizer 클래스를 사용해서
텍스트를 단어 기반으로 토큰화함으로써 Neural Network에 사용하기 적합한 형태로 변환하는 방법에 대해 소개합니다.
순서는 아래와 같습니다.
문자 기반 인코딩¶
지금까지 이미지 인식 예제에서는 이미지를 픽셀 단위의 숫자 기반으로 입력값으로 사용했습니다.
ASCII 코드를 이용해서 문자 기반 인코딩 (encoding)을 하면 어떠한 문제가 있을까요.
같은 문자로 이루어진 두 단어 ‘LISTEN’과 ‘SILENT’를 아래와 같은 ASCII 코드로 인코딩할 수 있습니다.

전혀 다른 의미를 갖는 이 두 단어는 같은 문자들의 집합이기 때문에 비슷한 숫자들로 인코딩되고,
따라서 Neural Network의 입력으로 사용하기에는 부적합합니다.
단어 기반 인코딩¶
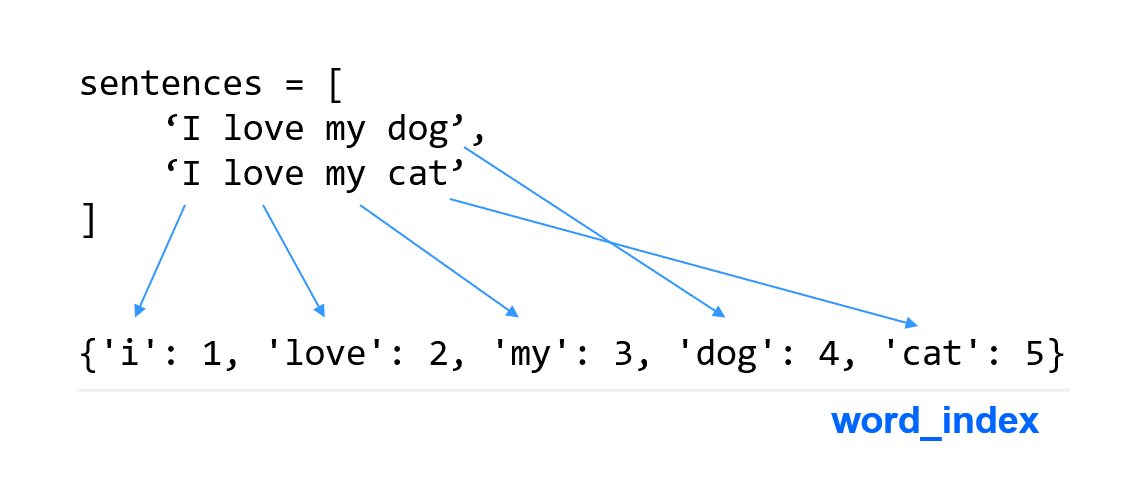
아래의 예제는 TensorFlow를 이용해서 두 문장 ‘I love my dog’과 ‘I love my cat’을 단어 기반으로 인코딩하는 방법을 보여줍니다.
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.preprocessing.text import Tokenizer
sentences = [
'I love my dog',
'I love my cat'
]
tokenizer = Tokenizer(num_words = 100)
tokenizer.fit_on_texts(sentences)
word_index = tokenizer.word_index
print(word_index)
{'i': 1, 'love': 2, 'my': 3, 'dog': 4, 'cat': 5}
TensorFlow와 Keras를 이용해서 단어를 인코딩하는 다양한 방식이 있지만 이 예제에서는 Tokenizer를 사용합니다.
Tokenizer는 문장으로부터 단어를 토큰화하고 숫자에 대응시키는 딕셔너리를 사용할 수 있도록 합니다.
예제에서 우선 두 개의 문장을 리스트 (sentences)의 형태로 만들었습니다.
Tokenizer의 인스턴스를 만들면서 num_words 파라미터를 이용해서 단어의 개수를 제한했습니다.
가장 자주 사용되는 num_words-1 개의 단어가 고려됩니다.
fit_on_texts() 메서드는 문자 데이터를 입력받아서 리스트의 형태로 변환합니다.
tokenizer의 word_index 속성은 단어와 숫자의 키-값 쌍을 포함하는 딕셔너리를 반환합니다.
출력 결과를 보면 대문자 ‘I’는 소문자 ‘i’로 변환된 것을 알 수 있습니다.
sentences = [
'I love my dog',
'I love my cat',
'You love my dog!'
]
tokenizer = Tokenizer(num_words = 100)
tokenizer.fit_on_texts(sentences)
word_index = tokenizer.word_index
print(word_index)
{'love': 1, 'my': 2, 'i': 3, 'dog': 4, 'cat': 5, 'you': 6}
sentences 리스트에 ‘You love my dog!’을 하나 추가했습니다.
출력 결과를 보면 ‘you’ 단어의 키가 추가되었고, ‘dog!’ 부분의 느낌표가 제거되어서 같은 단어로 인덱싱되었습니다.
느낌표, 마침표와 같은 구두점은 인코딩에 영향을 주지 않습니다.
텍스트를 시퀀스로 변환하기¶
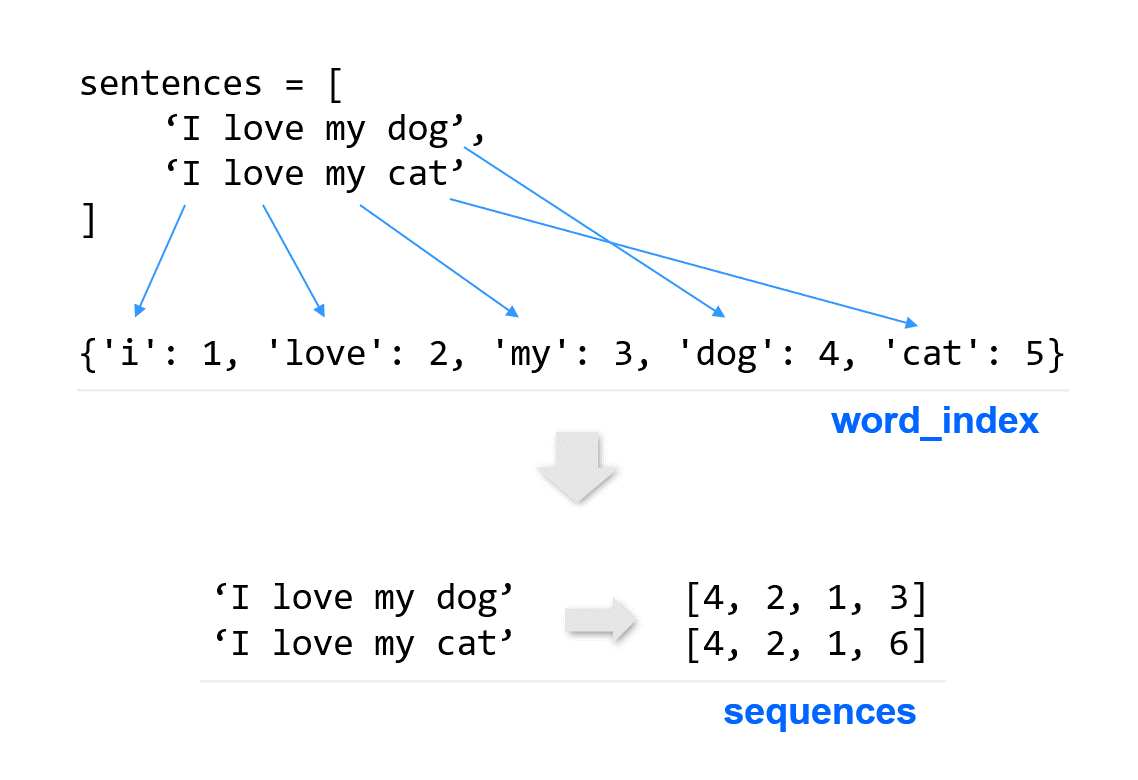
앞에서 Tokenizer를 이용해서 문장을 토큰화했습니다.
이제 texts_to_sequences() 메서드를 이용해서 이러한 단어들을 시퀀스의 형태로 변환해 보겠습니다.
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.preprocessing.text import Tokenizer
sentences = [
'I love my dog',
'I love my cat',
'You love my dog!',
'Do you think my dog is amazing?'
]
tokenizer = Tokenizer(num_words = 100)
tokenizer.fit_on_texts(sentences)
word_index = tokenizer.word_index
sequences = tokenizer.texts_to_sequences(sentences)
print(word_index)
print(sequences)
{'my': 1, 'love': 2, 'dog': 3, 'i': 4, 'you': 5, 'cat': 6, 'do': 7, 'think': 8, 'is': 9, 'amazing': 10}
[[4, 2, 1, 3], [4, 2, 1, 6], [5, 2, 1, 3], [7, 5, 8, 1, 3, 9, 10]]
texts_to_sequences() 메서드는 텍스트 안의 단어들을 숫자의 시퀀스의 형태로 변환합니다.
word_index를 출력해보면 ‘amazing’, ‘think’와 같은 새로운 토큰화된 단어들을 포함하는 딕셔너리를 확인할 수 있습니다.
sequences를 출력해보면 네 개의 문장이 숫자의 시퀀스로 변환된 것을 확인할 수 있습니다.
test_sentences = [
'i really love my dog',
'my dog loves my friend'
]
test_sequences = tokenizer.texts_to_sequences(test_sentences)
print(test_sequences)
[[4, 2, 1, 3], [1, 3, 1]]
새로운 단어들이 포함된 두 개의 문장을 texts_to_sequences()를 이용해서 시퀀스로 변환해보면,
미리 토큰화되어 있지 않은 ‘really’, ‘loves’와 같은 단어들은 숫자들의 시퀀스에 포함되지 않은 것을 알 수 있습니다.
토큰화되지 않은 단어 처리하기¶
자연어 처리에 있어서 많은 단어들을 학습하게 되고, 미리 토큰화되어 있지 않은 단어들을 만나게 됩니다.
앞의 예제와 같이 이런 단어들을 무시하기보다 oov_token 인자를 사용해서 특수한 값으로 처리할 수 있습니다.
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.preprocessing.text import Tokenizer
sentences = [
'I love my dog',
'I love my cat',
'You love my dog!',
'Do you think my dog is amazing?'
]
tokenizer = Tokenizer(num_words = 100, oov_token="<OOV>")
tokenizer.fit_on_texts(sentences)
word_index = tokenizer.word_index
sequences = tokenizer.texts_to_sequences(sentences)
test_sentences = [
'i really love my dog',
'my dog loves my friend'
]
test_sequences = tokenizer.texts_to_sequences(test_sentences)
print(test_sequences)
print(word_index)
[[5, 1, 3, 2, 4], [2, 4, 1, 2, 1]]
{'<OOV>': 1, 'my': 2, 'love': 3, 'dog': 4, 'i': 5, 'you': 6, 'cat': 7, 'do': 8, 'think': 9, 'is': 10, 'amazing': 11}
Tokenizer의 oov_token 인자를 사용하면 미리 인덱싱하지 않은 단어들은 ‘<OOV>’로 인덱싱됩니다.
패딩 설정하기¶
서로 다른 개수의 단어로 이루어진 문장을 같은 길이로 만들어주기 위해 패딩을 사용할 수 있습니다.
패딩을 사용하기 위해서는 tensorflow.keras.preprocessing.sequence 모듈의 pad_sequences 함수를 사용합니다.
pad_sequences() 함수¶
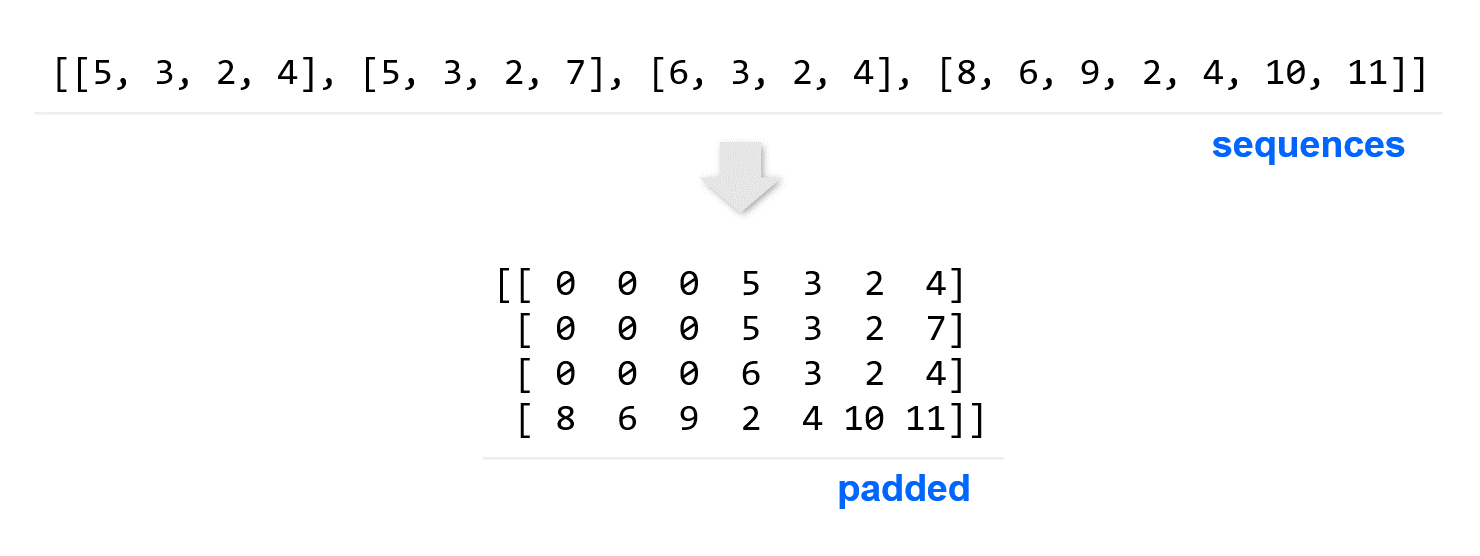
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
sentences = [
'I love my dog',
'I love my cat',
'You love my dog!',
'Do you think my dog is amazing?'
]
tokenizer = Tokenizer(num_words = 100, oov_token="<OOV>")
tokenizer.fit_on_texts(sentences)
word_index = tokenizer.word_index
sequences = tokenizer.texts_to_sequences(sentences)
padded = pad_sequences(sequences)
print(word_index)
print(sequences)
print(padded)
{'<OOV>': 1, 'my': 2, 'love': 3, 'dog': 4, 'i': 5, 'you': 6, 'cat': 7, 'do': 8, 'think': 9, 'is': 10, 'amazing': 11}
[[5, 3, 2, 4], [5, 3, 2, 7], [6, 3, 2, 4], [8, 6, 9, 2, 4, 10, 11]]
[[ 0 0 0 5 3 2 4]
[ 0 0 0 5 3 2 7]
[ 0 0 0 6 3 2 4]
[ 8 6 9 2 4 10 11]]
sequences는 정수의 시퀀스로 변환된 텍스트 문장입니다.
pad_sequences 함수에 이 시퀀스를 입력하면 숫자 0을 이용해서 같은 길이의 시퀀스로 변환합니다.
가장 긴 시퀀스의 길이가 7이기 때문에 모두 같은 길이의 시퀀스를 포함하는 NumPy 어레이로 변환되었습니다.
padding 파라미터¶
padded = pad_sequences(sequences, padding='post')
print(padded)
[[ 5 3 2 4 0 0 0]
[ 5 3 2 7 0 0 0]
[ 6 3 2 4 0 0 0]
[ 8 6 9 2 4 10 11]]
padding 파라미터를 ‘post’로 지정하면 시퀀스의 뒤에 패딩이 채워집니다. 디폴트는 ‘pre’입니다.
maxlen 파라미터¶
padded = pad_sequences(sequences, padding='pre', maxlen=6)
print(padded)
[[ 0 0 5 3 2 4]
[ 0 0 5 3 2 7]
[ 0 0 6 3 2 4]
[ 6 9 2 4 10 11]]
maxlen 파라미터는 시퀀스의 최대 길이를 제한합니다.
최대 길이를 6으로 지정하면 길이를 넘는 시퀀스는 잘라냅니다.
truncating 파라미터¶
padded = pad_sequences(sequences, padding='pre', maxlen=6, truncating='post')
print(padded)
[[ 0 0 5 3 2 4]
[ 0 0 5 3 2 7]
[ 0 0 6 3 2 4]
[ 8 6 9 2 4 10]]
truncating 파라미터는 최대 길이를 넘는 시퀀스를 잘라낼 위치를 지정합니다.
‘post’로 지정하면 뒷부분을 잘라냅니다.